目录
[TOC]
1.大体思路
主要思路是基于redis的INCR命令,redis的”INCR AND GET”是原子操作,同时Redis是单进程单线程架构,这样就不会因为多个取号方的INCR命令导致取号重复,因此,基于Redis的INCR命令实现序列号的生成基本能满足全局唯一与单调递增的序列号,但是这样生成的序列号只保证了递增这一特性。考虑到项目需求是需要生成特定规则的序列号,所以只依靠redis的INCR命令是实现不了的,最终我选择的是Hash提供的HINCRBY命令来实现。
2.Redis表结构设计
- 规则表
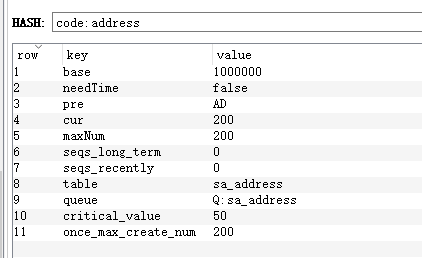
其中:
– base:序列号基数,用来限制序列号长度
– needTime:序列号是否增加时间属性
– pre:序列号前缀
– cur:当前序列号自然数大小
– maxNum:当前允许生成的最大序列号
– seqs_long_term:最近一小时序列号使用个数,用来动态控制生成序列号的个数
– seqs_recently:最近半小时序列号使用个数,用来动态控制生成序列号的个数
– table:对应数据库表名
– queue:序列号存放队列的key
– critical_value:临界值,当可用序列号数量小于等于临界值时,生成新的序列号
– once_max_create_num:一次允许生成的最大序列号个数
1. 序列号队列

采用的是字符串列表来储存生成的序列号,使用RPOP命令获取列表的最后一个元素;
3.具体实现
1. 生成并且保存序列号lua脚本
--- 生成并且保存序列号
local function check(maxNum, needTime, pre, base, cur, queue)
if maxNum == nil or needTime == nil or pre == nil or base == nil or cur == nil or queue == nil
then
return false;
else
return true;
end
end
local function creatSeqAndSave(RULE_KEYS, SAVE_QUEUE, NUM, prefix, needTime, base)
for i = 0, (NUM - 1) do
local seq = redis.pcall('HINCRBY', RULE_KEYS, 'cur', 1);
local seq_res;
if needTime == 'true'
then
seq_res = prefix .. os.date("%Y%m%d", os.time()) .. (seq + base);
else
seq_res = prefix .. (seq + base);
end
redis.pcall('LPUSH', SAVE_QUEUE, seq_res);
end
end
local function hashIncrNumberAndSave(RULE_KEYS, NUM)
-- max 当前情况下允许生成的最大序列号
local maxSeqNumStr = redis.pcall('HGET', RULE_KEYS, 'maxNum');
-- 是否需要计入时间
local needTime = redis.pcall('HGET', RULE_KEYS, 'needTime');
-- prefix 序列号前缀
local prefix = redis.pcall('HGET', RULE_KEYS, 'pre');
-- base 序列号基数
local base = redis.pcall('HGET', RULE_KEYS, 'base');
-- 当前序列号
local cur = redis.pcall('HGET', RULE_KEYS, 'cur');
local SAVE_QUEUE = redis.pcall('HGET', RULE_KEYS, 'queue');
-- 必要参数校验
local checkRes = check(maxSeqNumStr, needTime, prefix, base, cur, SAVE_QUEUE);
if type(checkRes) == 'boolean' and checkRes == false
then
return { 'F', '缺少基础数据' };
end
local maxSeqNum = tonumber(maxSeqNumStr);
-- 此次允许生成的最大序列号
local allowMax = tonumber(cur + NUM);
if allowMax < maxSeqNum then
creatSeqAndSave(RULE_KEYS, SAVE_QUEUE, NUM, prefix, needTime, base);
elseif tonumber(cur) < maxSeqNum and maxSeqNum <= allowMax then
NUM = maxSeqNum - cur;
creatSeqAndSave(RULE_KEYS, SAVE_QUEUE, NUM, prefix, needTime, base);
else
return { 'F', '当前序号大于最大允许值,不在生成新的序号' };
end
if redis.pcall('HGET', RULE_KEYS, 'cur') < redis.pcall('HGET', RULE_KEYS, 'maxNum')
then
return { 'S' };
else
return { 'C' };
end
end
-- 调用 生成序列号并保存 方法
return hashIncrNumberAndSave(KEYS[1], ARGV[1]);
- 获取序列号lua脚本
--- 从对应规则的队列取出 序列号
local function getSeqNum(ruleKey)
local queueKey = redis.pcall('HGET', ruleKey, 'queue');
if queueKey == nil
then
return nil;
end
redis.pcall('HINCRBY', ruleKey, 'seqs_long_term', 1);
redis.pcall('HINCRBY', ruleKey, 'seqs_recently', 1);
return redis.pcall('RPOP', queueKey);
end
return getSeqNum(KEYS[1]);
- 检查序列号使用情况lua脚本
--- 检查序列号使用情况
local function checkSeqNum(ruleKey)
local queueKey = redis.pcall('HGET', ruleKey, 'queue');
if queueKey == nil
then
return nil;
end
local queueKeyLength = redis.pcall('LLEN', queueKey);
local seqsRecently = redis.pcall('HGET', ruleKey, 'seqs_recently');
local seqsLongTerm = redis.pcall('HGET', ruleKey, 'seqs_long_term');
local criticalValue = redis.pcall('HGET', ruleKey, 'critical_value');
local onceMaxCreateNum = redis.pcall('HGET', ruleKey, 'once_max_create_num');
return { queueKeyLength, tonumber(seqsRecently), tonumber(seqsLongTerm), tonumber(criticalValue), tonumber(onceMaxCreateNum) };
end
return checkSeqNum(KEYS[1]);
- 设置最大允许生成的序列号的lua脚本
--- 设置最大允许生成的序列号
local function setMaxNum(ruleKey, step)
local maxNum = redis.pcall('HGET', ruleKey, 'maxNum');
if maxNum == nil
then
redis.pcall('HSET', ruleKey, 'maxNum', step);
return step;
end
local max = tonumber(maxNum) + tonumber(step);
redis.pcall('HSET', ruleKey, 'maxNum', max);
return redis.pcall('HGET', ruleKey, 'maxNum');
end
return setMaxNum(KEYS[1], ARGV[1]);
- 设置最大允许生成的序列号和当前序列号大小的lua脚本
--- 设置最大允许生成的序列号和当前序列号大小
local function setMaxNumAndCur(ruleKey, max)
max = tonumber(max);
local maxNum = tonumber(redis.pcall('HGET', ruleKey, 'maxNum'));
local cur = tonumber(redis.pcall('HGET', ruleKey, 'cur'));
if maxNum == nil
then
redis.pcall('HSET', ruleKey, 'maxNum', max);
return ;
end
if cur < max
then
redis.pcall('HSET', ruleKey, 'cur', max);
if maxNum < max
then
redis.pcall('HSET', ruleKey, 'maxNum', max);
return ;
end
end
return max;
end
return setMaxNumAndCur(KEYS[1], ARGV[1]);
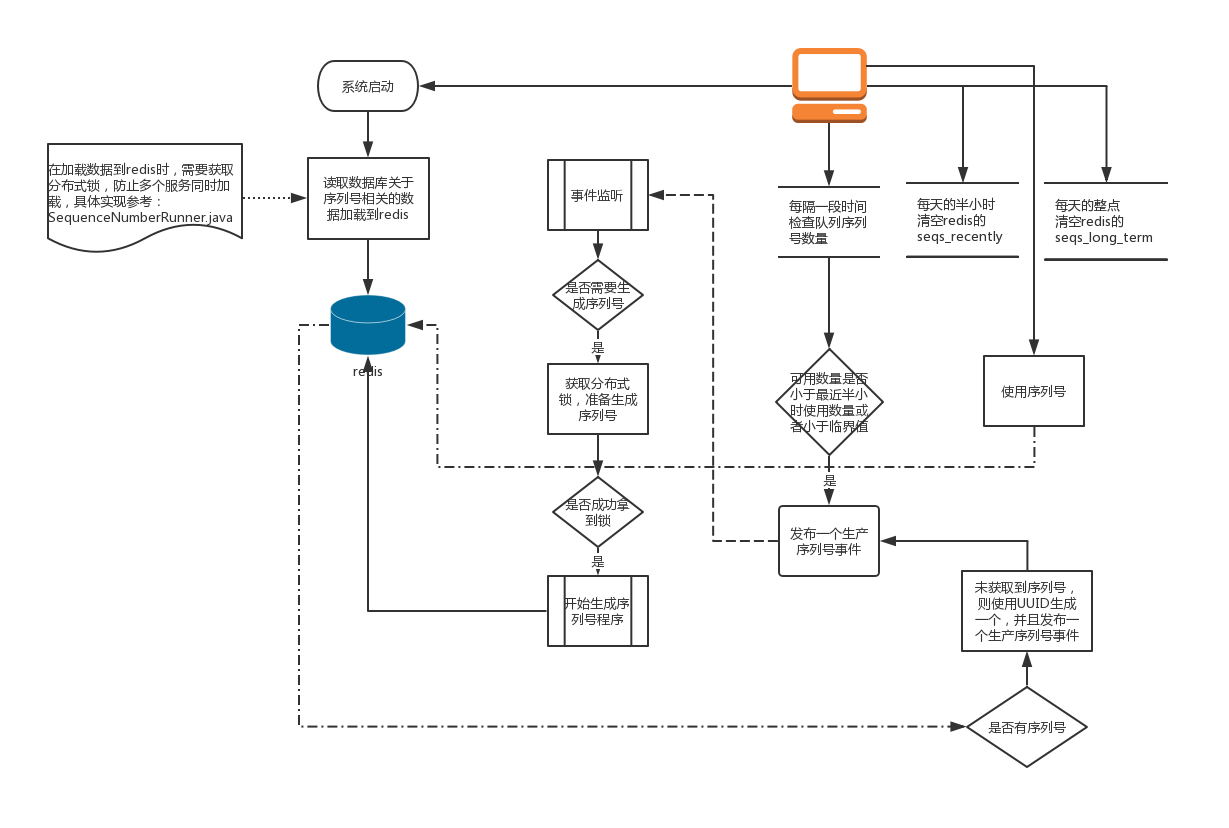
系统启动后首先是把数据库关于redis的一些数据加载到redis,然后系统通过一个job,定时去检查序列号队列可用数量和最近半小时、最近1小时使用情况进行对比,决定是否需要生成新的序列号,生成序列号的数量根据最近一小时使用数量、最近半小时使用数量和系统配置的一次最多生成序列号数量决定。如果可用数量小于系统配置的临界值数量,也会触发生成序列号事件。监听到生成序列号生成事件,就会马上由拿到分布式锁的服务进行生成新的序列号。这里采用事件监听机制,是把使用序列号和生产序列号服务解耦。系统启动后会有job定时对最近半小时使用数量和最近一小时使用数量进行归零操作;这里使用两个变量来统计序列号使用情况,目的是可以动态的根据实际使用情况,生产满足需求的序列号数量,防止生产过多的序列号。做的高峰期时,生产的序列号就多,底谷时生成序列号少的需求。
4.宕机恢复问题
Redis宕机问题
Redis在提供高性能存取的同时,支持RDB和AOF持久化,来保证宕机后的数据恢复。
1. RDB持久化
如果开启RDB持久化,由于最近一次快照时间和最新一条 HINCRBY命令的时间有可能存在时间差,宕机后通过RDB快照恢复数据集会发生生产出重复的序列号。
1. AOF持久化
如果使用AOF持久化,通过追加写命令到AOF文件的方式记录所有Redis服务器的写命令,不会发生取号重复的情况。但AOF持久化会损耗性能并且在宕机重启后可能由于文件过大导致恢复数据时间过长,并且通过AOF重写来压缩文件,在写AOF时发生宕机导致文件出错,则需要较多时间去人为恢复AOF文件。
所以无论你采用哪一种方式,想通过redis持久化文件来恢复数据都不是最优的方案。这里我采用的是直接获取数据库保存的最大允许生成序号值(maxNum),直接覆盖redis的cur和maxNum,这样可能会导致序列号不连续,但是后续生产的序列号还是连续的,也不会出现重复现象;具体恢复方案如下:
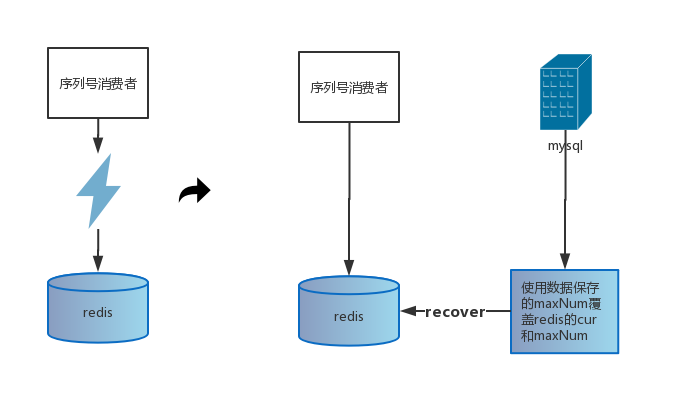
MySQL宕机问题
由于取序列号操作在Redis,所以当数据库宕机时,可适当调整redis的maxNum,以提供足够时间恢复mysql